
Gateway Matrix Remodeled
 Gateway Matrix Remodeled
Gateway Matrix Remodeled
From so-called experts and politicians we always hear talk about vaping as the possible "Gateway to Smoking". Everybody knows--or at least should know--there is more than one possible gateway. Clive Bates described them in his blog post. Riccardo Polosa et al. presented A Risk Assessment Matrix for Public Health Principles: The Case for E-Cigarettes. That inspired me to quantify the gateways in a probability matrix.
But first I found that I had to find a metric to evaluate the output of such a matrix. A basically very simple concept came to mind: The Total Harm Risk Metric (THRM) was born.
![]() This is part two of video poster #32 presented at the Global Forum on Nicotine (GFN) 2019.
This is part two of video poster #32 presented at the Global Forum on Nicotine (GFN) 2019.
You find the raw poster (without sound) here: <click>
An edited version with audio comment will soon be published on our youtube channel.
Back to the Gateways ...
The Problem
When survey results are presented, concerned comments about "Vaping as a possible Gateway to Smoking" seem inevitable. But is it really just a one way street as those comments insinuate?

What about other possible Gateways?
Reality is a Matrix
Well, there actually is a Gateway from each behavior to each other. Including itself. What we have here is a square Matrix where none fall out of the system and they all end up in one category or another. How many of the original set stay in the same behavioral group, and how many take the Gateway to another, all depends on the probability of the individual Gateway. Like this:
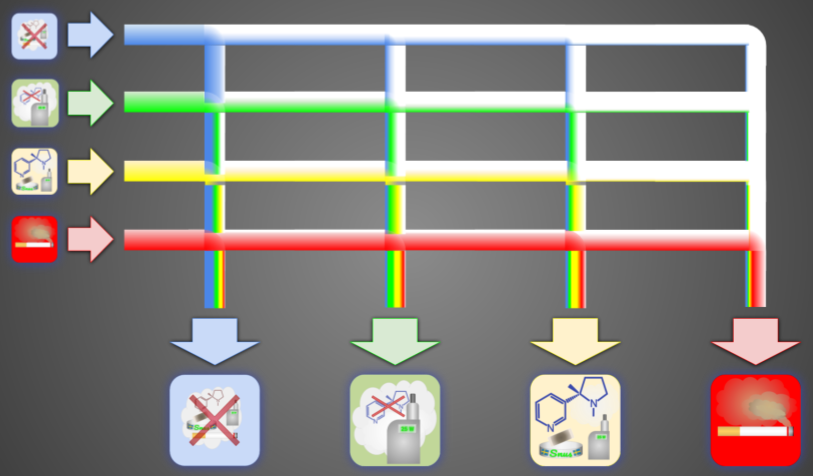
But of course the Matrix is more complex than this, since there are many more distinct categories, like those I identified in THRM.
Attractivity
The hard part is to guesstimate reasonable probabilities for each Gateway.
It's even harder, because a useful model also works with environmental variables that have an influence on the results. To keep it simple I only use a single variable with a linear influence on the probabilities. This would be a factor describing an "Attractivity" of smokeless products in general. Many influences are accumulated into it:

Weights
For each row in the Gateway Probability Matrix the total sum must be 1.0. One way to manage this is to use arbitrary weights that are all relative to the other weights in only the same row. In the end all weights are added and the weight for each column is divided by this sum. Resulting in the actual probability.
There are two sets of weights. One is the static weight that is the constant base value.

The other is the dynamic weight. Each number here will be multiplied by the Attractivity before it's added to the static weight value to create the adjusted column weight.

Finding reasonable weights is a bit tricky. I started with what seemed plausible. Then I tweaked the numbers so that the results of the model (see below) roughly fit to the data from the NYTS studies. More time, effort, and some intelligent (genetic?) algorithm could produce a much better fit.
Probabilities
The resulting probability matrix is the core of the modeling. Only one environmental variable has an external influence on the model: the Attractivity.

The process itself is very simple:
- start with a known vector of data
- calculate the probability matrix according to the next selected Attractivity
- do a matrix multiplication with the input vector
- the resulting vector is also the input for the next iteration (2.)
Model compared to NYTS
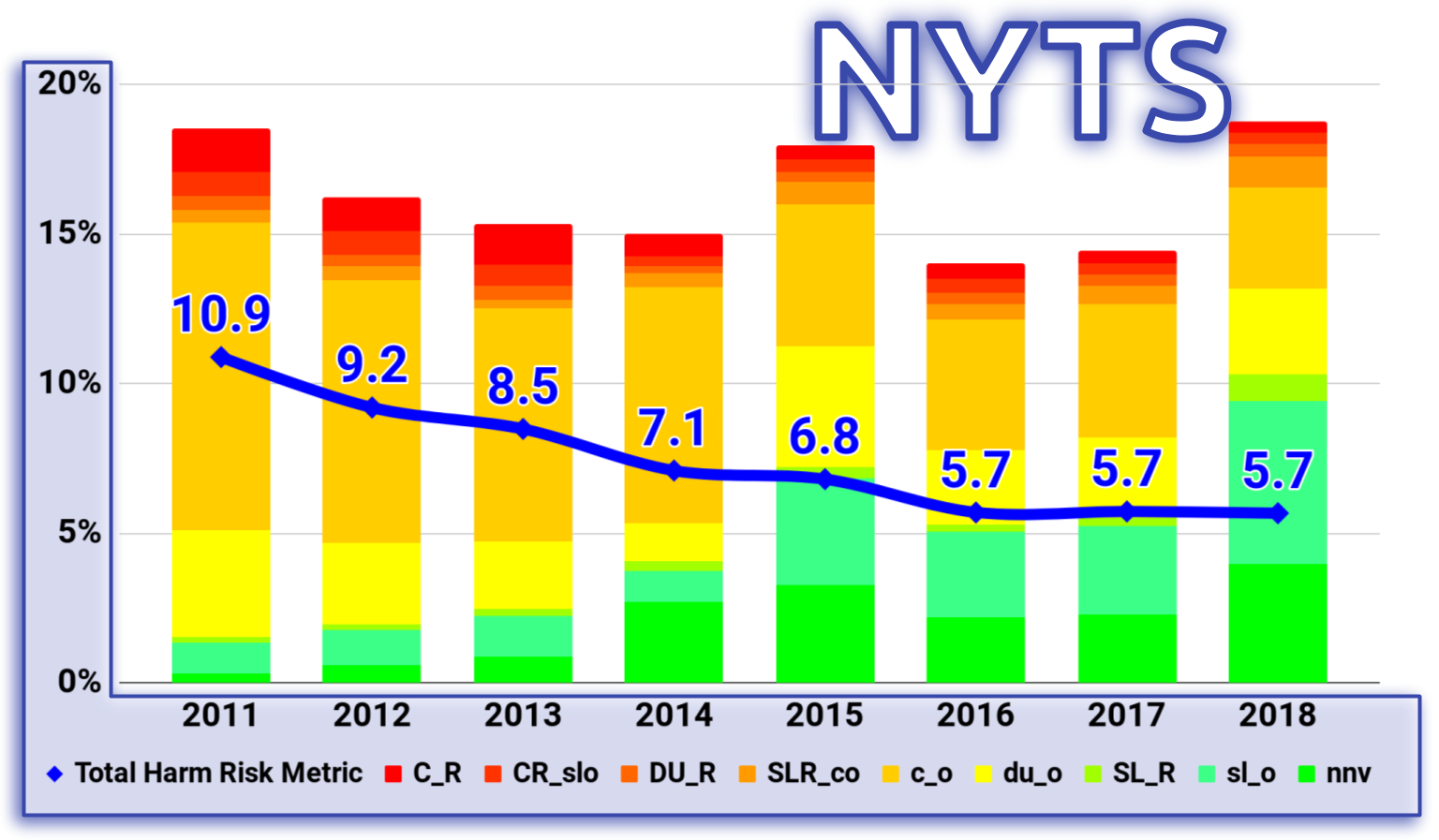
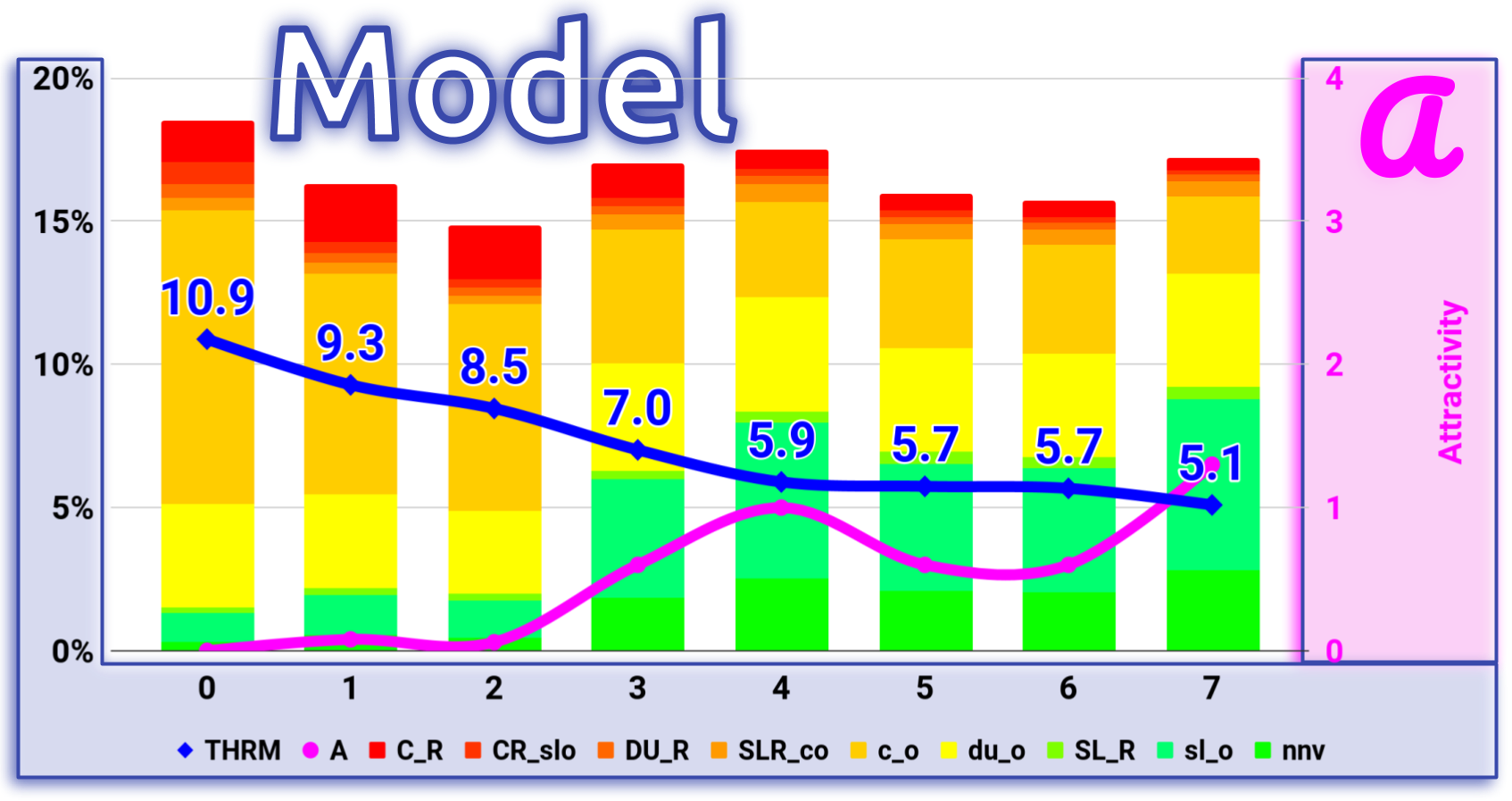
Possible futures
Starting with the NYTS data from 2018 I calculated the model for different scenarios from total reduction of the Attractivity via prohibitive regulations and propaganda to massive support to increase it. Here are some results:
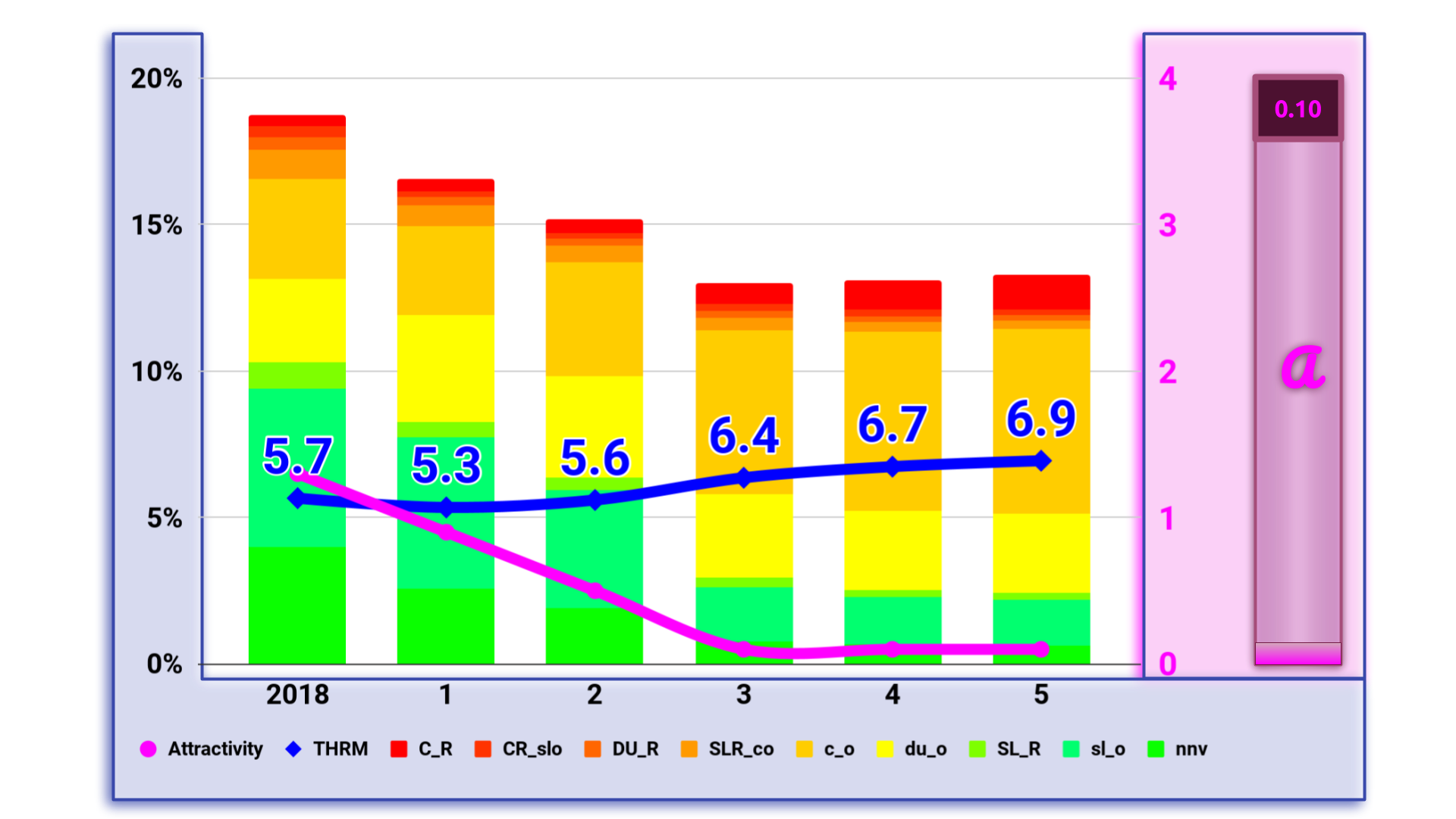
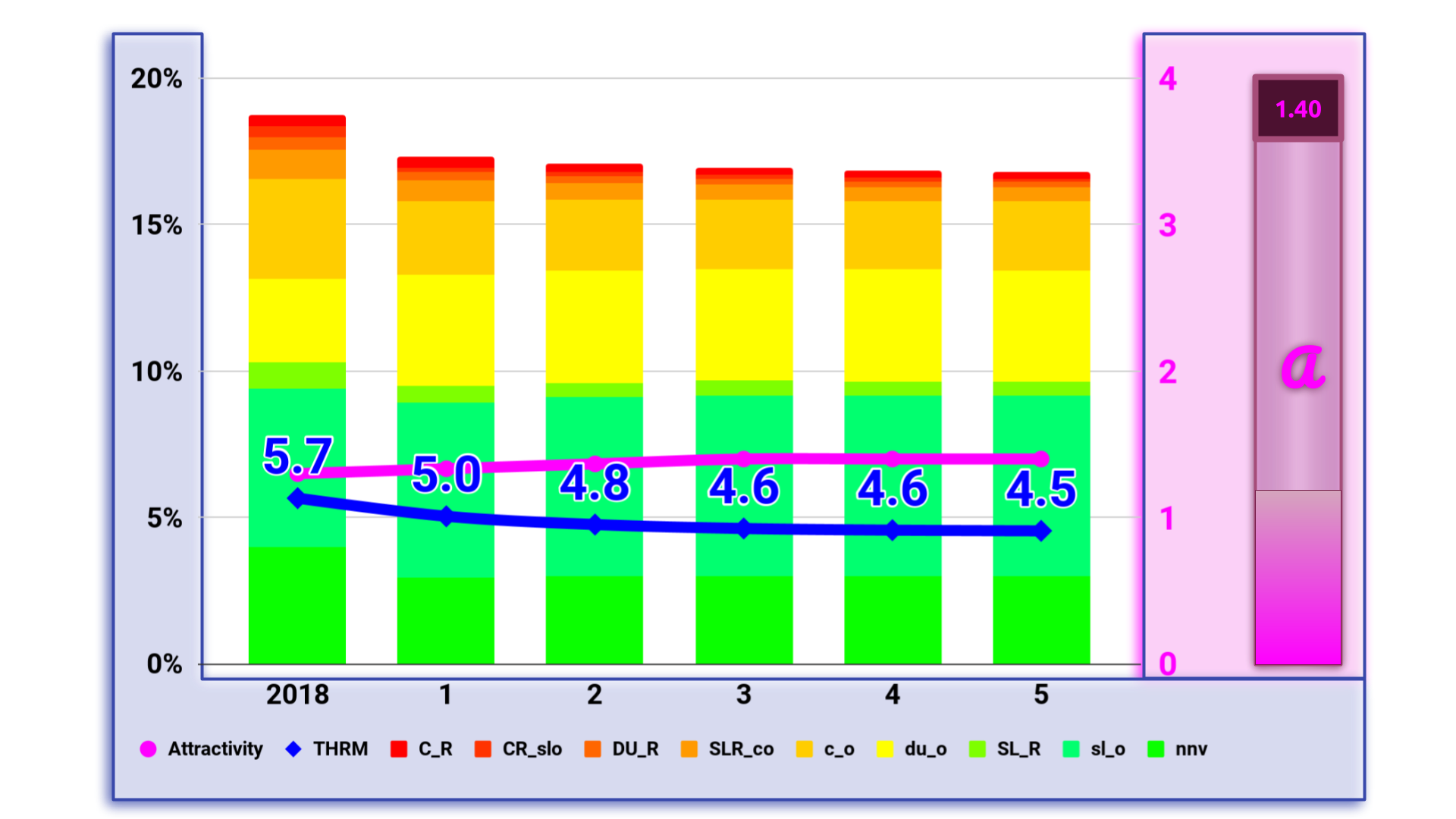
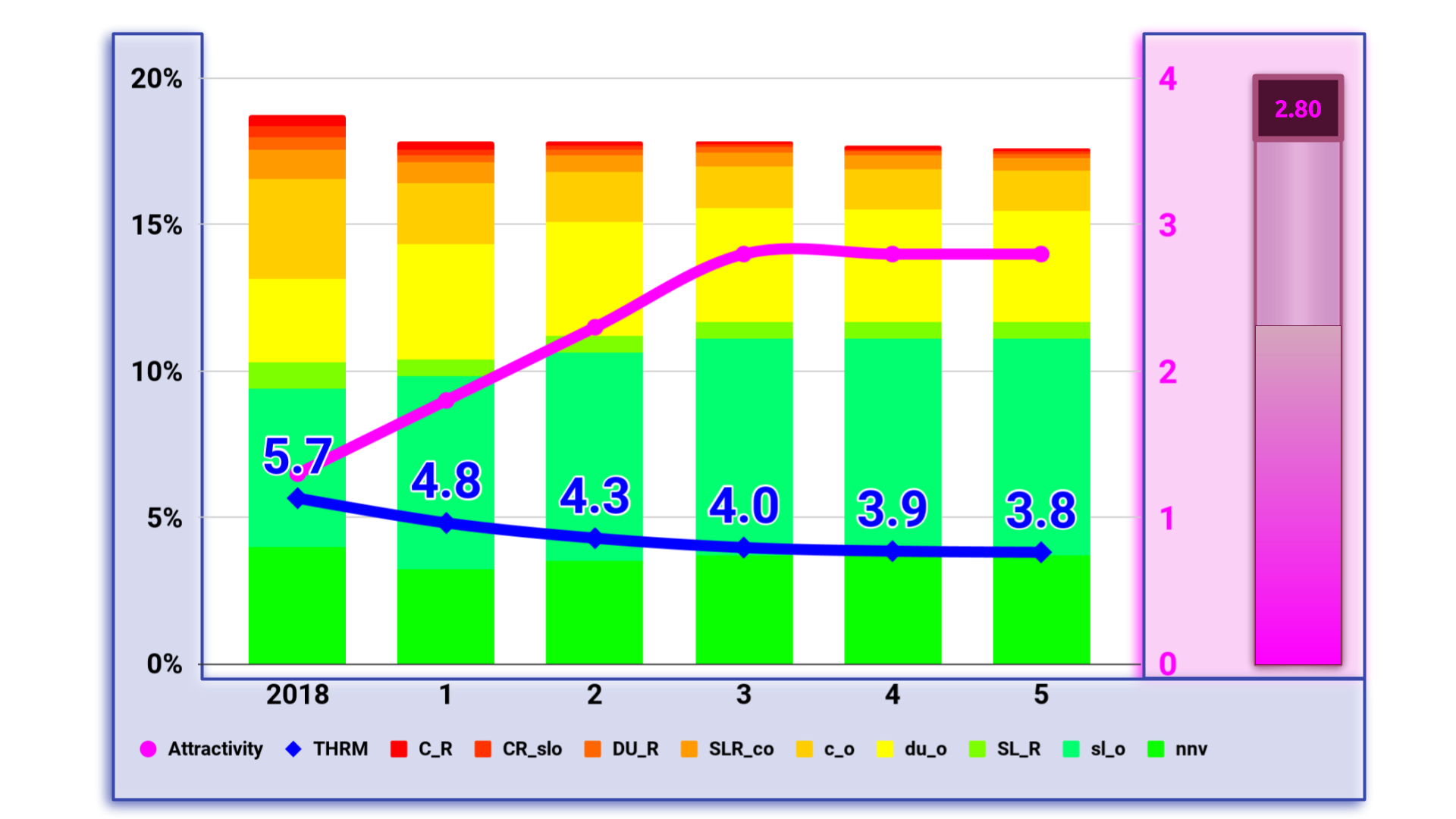
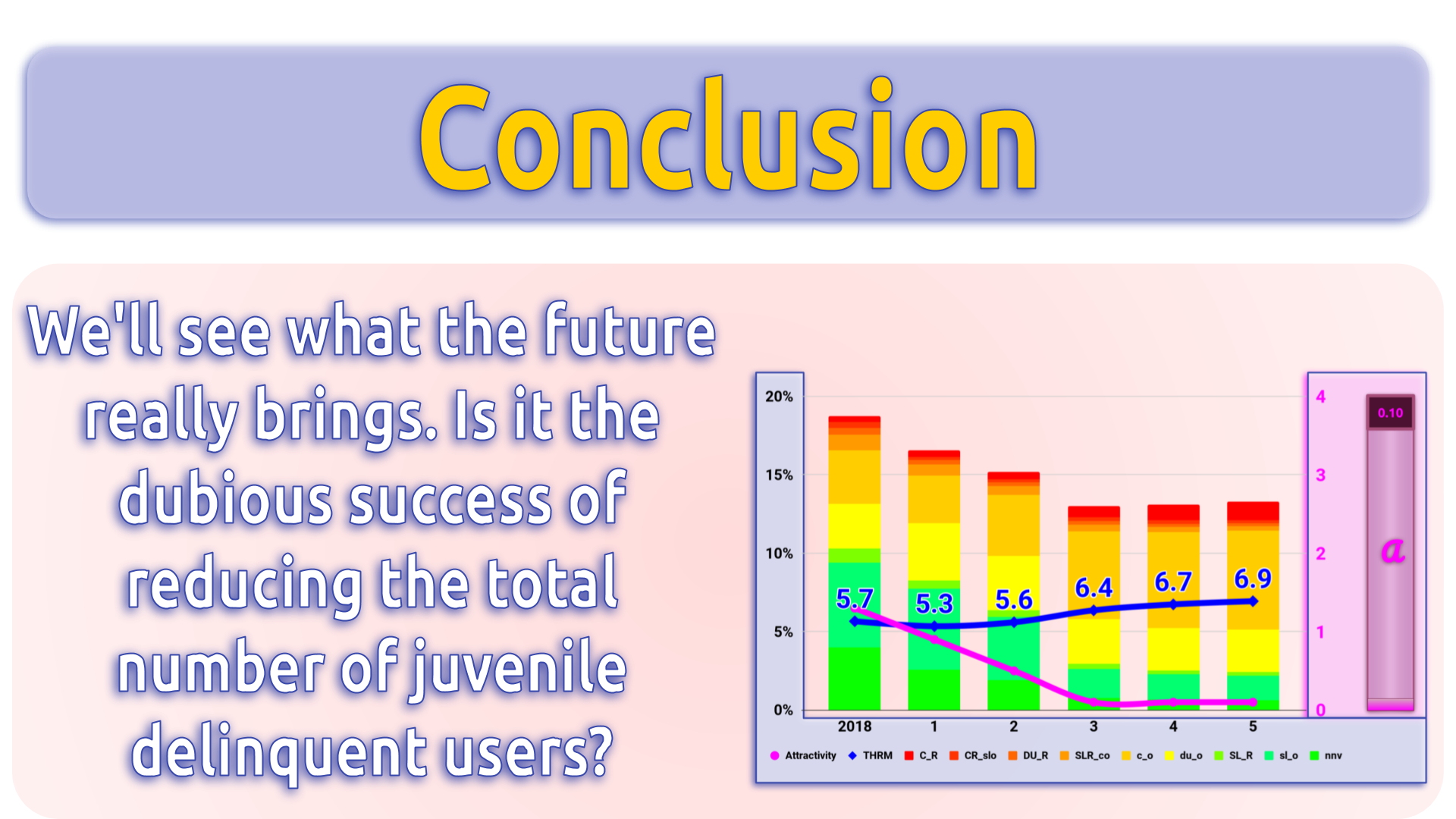
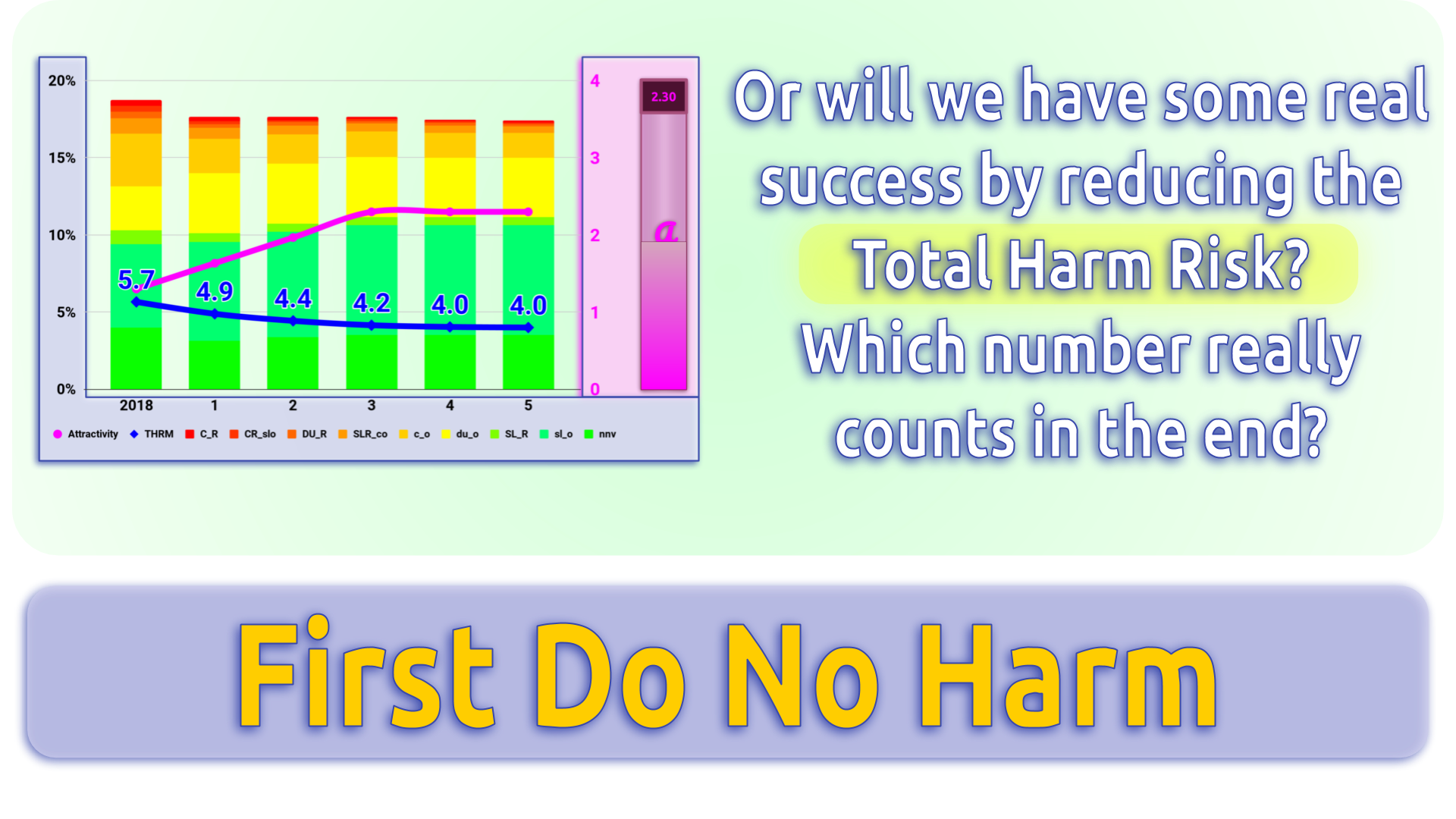
Conclusion
4 Gedanken zu „GFN 2019 – Gateway Matrix“
Da wäre eine deutsche Übersetzug sicher spannend.
Ihr wollt doch deutsche Dampfer erreichen oder nicht ?
Hallo Thomas, danke für den Hinweis, und wir arbeiten bereits dran. Wird trotzdem noch ein kleines Weilchen dauern.
LG, Hazel
Hello, are you able to share the video with sound?
We are working on it.